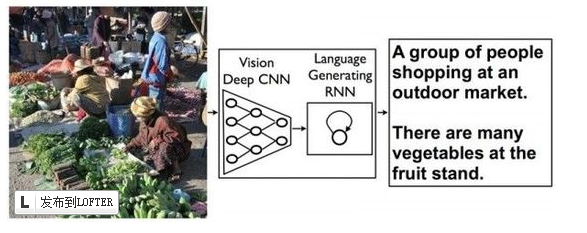
来自谷歌研究院的科学家发表了一篇博文,展示了谷歌在图形识别领域的最新研究进展。或许未来谷歌的图形识别引擎不仅仅能够识 别出照片的对象,还能够对整个场景进行简短而准确的描述。这个突破性概念来自于机器语言翻译方面的研究成果:通过一种递归神经网络(RNN)将一种语言的 语句转换成向量表达,并采用第二个RNN将向量表达转换成目标语言的语句。
而谷歌将以上过程中的第一种RNN用深度卷积神经网络CNN取代,这种网络可以用来识别图像中的物体。通过此种方法,就可以实现将图像中的对象转换成语句,对图像场景进行描述。概念虽然简单,但是实现起来十分复炸,科学家表示目前实验产生的语句合理性不错,但距离完美仍有差距,这项研究目前仅处于早期阶段。比如下述例子展示了通过此方法识别图像对象,并产生描述的过程。